Meta Learning
학습하는 과정을 학습하다. Meta learning은 현재 AI에서 가장 유망하고 트렌디한 연구분야로 AGI(Artificial General Intelligence)로 나아갈 수 있는 매우 중요한 디딤돌이라고 볼 수 있다. AGI란 ‘일반 인공
rhcsky.tistory.com
앞의 글에서 메타 러닝에 대해 읽어봤다면 few shot learning에 대해 흥미를 갖기 시작할 것 같아요. 오늘은 few shot learning과 비슷한 one shot learning에 대해 다룬 논문을 하나 리뷰해 보려고 합니다. One shot learning은 n-way k-shot에서 k=1인 few shot learning이라고 생각하면 됩니다. 논문 리뷰는 주관적인 해석 와 오역이 있을 수 있으니 잘못된 내용이 있다면 언제든지 알려주세요!
리뷰할 논문은 Siamese Neural Networks for One-shot Image Recognition으로 Siamese Network를 이용하여 class당 하나의 이미지를 가지고 recognition을 하는 모델에 대해 설명한다.
Abstract
현재 머신 러닝의 문제점과 이를 해결하기 위한 방안으로 siamese neural networks를 제안한다.
머신 러닝은 현재 다양한 분야(web search, spam detection, caption generation, speech and image recognition)에서 매우 활발하게 연구가 되고 있지만, 좋은 특징을 학습하기 위해서는 많은 데이터가 필요하고 그에 따른 계산 비용이 발생한다. 즉 이러한 알고리즘은 supervised learning(지도 학습)으로 많은 데이터를 확보하지 못한다면 아무리 좋은 모델이어도 제대로 된 성능을 발휘하지 못한다.
이 논문은 이렇게 데이터가 부족한 상황에서 추가적인 학습(retraining) 없이 새로운 class에 대해서도 좋은 성능을 낼 수 있는 모델을 설계하는 것을 목적으로 작성되었다. 사람은 새로운 개념에 대해 빠르게 학습할 수 있는데 머신 러닝도 이와 비슷한 흉내를 내보겠다는 것이다.
즉, 보통의 머신 러닝은 새로운 class가 생기면 그 class를 포함하여 다시 학습을 해야 하는데 이 때, 데이터가 많지 않으면 새로운 class에 대해서 제대로 학습할 수 없다. 따라서 이러한 기존의 한계를 극복하기 위해 one shot learning 기법을 이용한 모델을 개발한다는 말인 것 같다.
Approach
네트워크를 어떻게 학습할지 접근하는 방법을 제시한다.
Siamese neural networks와 supervised metric을 통하여 Image representation을 학습한다. 학습 후, retraining 없이 network's features를 통해 one-shot learning을 할 수 있다.
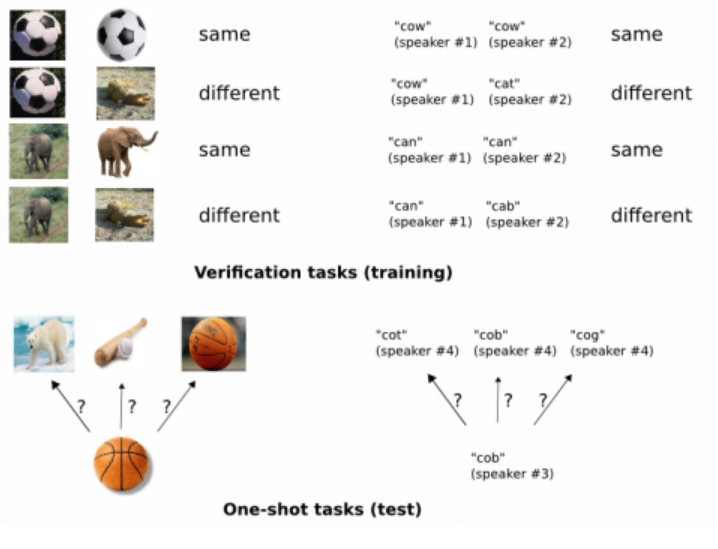
이 논문에서는 character recongnition에 초점을 맞추어 진행하지만 일반적인 종류에도 사용할 수 있고 아래와 같은 특징을 같는다.
a) capable of learning generic image features useful for making predictions about unknown class distributions even when very few examples from these new distributions are available
--> 일반적인 이미지의 특징을 가지고 새로운 class에 대해서도 모델을 사용할 수 있다.
b) easily trained using standard optimization techniques on pairs sampled from the source data
--> 샘플링된 이미지 쌍을 쉽게 학습할 수 있다.
c) provide a competitive approach that does not rely upon domain-specific knowledge by instead exploiting deep learning techniques.
--> 딥러닝 기법을 사용하여 도메인별 지식에 의존하지 않고 경쟁적인 접근법을 제공한다.(?)
학습하는 방법은 위의 그림처럼 두 개의 input을 넣고 두 input이 같은 class인지 다른 class인지 labeling을 해준다. 즉, 두 개의 이미지를 보여주면 same, different를 output으로 내는 모델을 학습하는 것이다. 모델이 alphabets의 하나의 set에 대해 제대로 학습했다면 특징을 학습하기 위해 다양한 변화에 노출되고 다른 알파벳에 대해서도 잘 구별할 수 있을 것이다.
Related Work
관련 논문. 중요한 내용이 없는 것 같아 가볍게 넘어간다.
One-shot learning은 아직 미숙하고 관심이 많지 않지만, 몇 개의 key lines가 있다.
- Variational Bayesian framework으로 one-shot image classification (Fe-Fei 2003, 2006)
- point of view of cognitive science (Lake)
- Hierarchical Bayesian Program Learning (HBPL, 2013)
- Hierarchical Hidden Markov model for speech primitives combined with a Bayesian inference procedure (2014)
- Bayesian networks to predict attributes for Ellis Island passenger data (2009)
- Wu and Dennis address one-shot learning in the context of path planning algorithms for robotic actuation (2012)
Deep Siamese Networks for Image Verification
Siamese networks의 구조에 대해 설명한다.

Siamese networks는 내부에 두 개의 sub network가 존재한다. input image가 pair로 존재하기 때문에 각각의 이미지를 sub network에 넣어 output 두 개를 만들고 두 output을 통해 distance를 산출한다. 이 때 두 sub networks의 parameters는 공유된다. 샴 네트워크(Siamese networks)는 symmetric 하기 때문에 (A, B)의 산출 값과 (B, A)의 산출 값이 같아야 한다. 따라서 논문에서는 feature vector h1, h2 사이에 L1 distance를 계산하고 activation function으로 sigmoid를 사용하여 0과 1사이로 output을 낸다. (0: different, 1: same) 따라서 이때 loss function은 binary cross-entropy를 사용한다.

Model
Model은 각각 $N_l$ 단위를 갖는 L layers의 샴 뉴럴 네트워크이다. $h_1,l$은 layer &l&의 첫 번째 twin에서의 hidden vector를 나타내고 $h_2, l$은 두 번째 twin의 hidden vector이다. 그리고 처음 L-2 layers에서 ReLU를 사용하고 나머지에서는 sigmoidal units을 사용한다.
Convolution layers는 다양한 크기의 single channel, fixed stride 1, 16 배수의 filters, ReLU activate function으로 구성되고 optional 하게 max-pooling을 사용한다. 이를 수식으로 나타내면 아래와 같다.
$$a^{(k)}_{1, m} = max-pool(max(0, W^{(k)}_{l-1, l} * h_{1, (l-1)} + b_l ),2)$$
$$a^{(k)}_{2, m} = max-pool(max(0, W^{(k)}_{l-1, l} * h_{2, (l-1)} + b_l ),2)$$
$W_{l-1, l}$은 layer $l$에 대한 feature maps를 3차원으로 나타낸 tensor이고 $*$는 각 convolutional filter와 input feature maps 사이의 출력 단위만 반환하는 valid convolutional operation이 되도록 하였다. 즉 입, 출력 사이에 사이즈를 맞춘다는 의미이다.
The unit of final convolutional layer는 flatten to single vector가 된 후, 아래와 같이 distance를 구한다.
$$ \boldsymbol p = \sigma (\sum_{j} \alpha|h^{j}_1 - h^{j}_2|) $$
$\sigma$는 sigmoidal activation function을 사용한다는 뜻이며, $j$번 째 일 때 첫 번째 이미지의 feature vector와 두 번째 이미지의 feature vector끼리 L-1 distance를 구한 뒤, parameter $\alpha$를 곱해서 probability를 구한다. $\alpha$는 weight으로 학습에 의해 update 되는 parameter이다.
Learning
Loss Function : binary classification으로 학습하므로 regularized binary cross-entropy를 따른다.
Optimization : Momentum GD, minibatch size 128, initial learning rate 0.1, initial momentum 0.5
Weight Initialization : normal distribution(mean, std)
- Convolutional layer
- Weight = (0, 0.01)
- Biases = (0.5, 0.01)
- FC layer
- Weight = (0,0.01)
- Biases = (0,0.2)
Learning Schedule :
- Leraning rate는 1 epoch당 1%씩 감소하게 적용, $lr^T = 0.99 lr^T-1$
- Momentum은 선형하게 증가
- 최대 200 epoch까지 학습을 시켰으나 20 epoch이상 validation acc가 상승하지 않을 경우 early stopping
Hyperparameter optimization :
- Learning rate : $[1e^-s,1e^-1]$
- Momentum : [0,1]
- Regularization weight: [0,0.1]
- Convolutional filters size : 3x3 to 20x20
- Convolutional filters number : 16 to 256 (multiples of 16)
- FC layers: 128 to 4096 units (multiples of 16)
Affine distortions : Augmentation 적용
Experiments

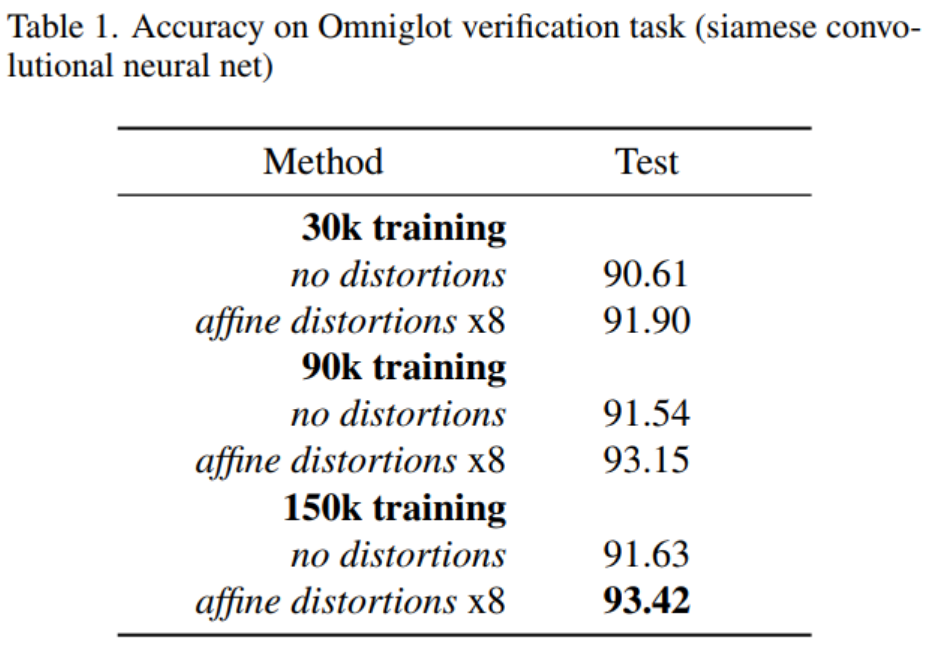
논문에서는 20-way 1-shot learning을 진행하고 데이터셋은 Omniglot dataset을 사용해 모델을 학습한다. Omniglo dataset이란 50개 언어의 알파벳 데이터를 의미한다. 각 언어당 15~50개의 alphabet characters를 가지고 있다. 그리고 각 alphabet characters 당 20개의 data가 존재하는데 이 20개는 글씨를 쓴 사람이 각각 다르다. 40개의 Backgroud set과 10개의 evaluation set으로 구성하였는데 background set은 훈련할 때 사용하고 evaluation set은 성능을 측정할 때 사용한다. Background set은 다시 train data와 validation data로 구성되고 evaluation set은 test data로 구성된다.
논문에서는 학습을 위해 총 30k, 90k, 150k 쌍의 데이터를 만든다. 이 쌍은 50%의 same image pair와 50%의 different image pair이다. 데이터 쌍을 만드는 순서는 아래와 같다.
- 40개의 backgroud set에서 30개를 train data로 10개는 validation data로 나눈다.
- 30개의 train set에서 20명의 사람이 쓴 이미지 중 12명의 이미지만 고른다.
- 즉, 30개의 alphabet에서 12명의 사람이 쓴 이미지만 추려와서 30k, 90k, 150k만큼의 이미지 쌍을 만든다.
- 여기서 8개의 transform을 이용하여 augmentation을 통해 이미지 데이터를 증폭한다. 총 270k, 810k, 1350k 개의 이미지 쌍이 생성된다.
One-shot learning에서는 evaluation 방법이 평소에 알던 머신 러닝 방법과 다르다. 기존의 방법은 이미지 쌍을 input으로 넣고 same인지 different인지 맞추는 방식이었지만 20-way 1-shot learning이기 때문에 한번에 20개의 class에 대해 판단할 수 있어야 한다. 따라서 논문에서는 $C^* = argmax_cP^{(c)}$로 maximum similarity를 계산해서 accuracy를 판단한다. 한 번 accuracy를 계산할 때 20개의 이미지 쌍이 존재해야 하고, 20개의 이미지 쌍 중 첫 번째 이미지는 모두 같은 이미지로 만든다. 두 번째 이미지는 첫 번째만 같은 class의 이미지, 나머지는 첫 번째 이미지와 다른 class의 이미지를 선택해야 한다. 이때, 이미지는 validation data 혹은 test data에서 선택해야 한다. test data를 만드는 순서는 다음과 같다.
- validation data 와 test data를 합친 dataset을 만든다.
- 총 20개의 이미지 쌍을 만들어야 하는데 첫 번째 이미지는 모두 같은 이미지로 선택한다.
- 하나의 class를 결정해서 첫 번째 이미지로 선택한다.
- 두 번째 이미지는 첫 번째 이미지와 다른 class의 이미지를 선택한다.
- 첫 번째 이미지는 3번에서 결정한 이미지를 넣고, 두 번째 이미지는 4번을 반복해서 총 20개의 이미지 쌍을 만든다.
- 이때, 20개의 이미지 쌍 중 첫 번째 이미지 쌍의 두 번째 이미지는 첫 번째 이미지와 같은 class로 한다.
- 즉, 20개의 쌍 중 1개의 쌍만 같은 class를 갖게 구성해야 한다.
이렇게 만들어진 이미지 데이터를 모델에 넣고 output을 산출하면 첫 번째 이미지에 대한 두 번째 이미지의 similarity가 나온다. 20개의 similarity 중 1번 similarity 가 가장 높아야 model이 올바르게 예측했다고 판단한다. 첫 번째 이미지 쌍만 같은 class이고 나머지는 다른 class이기 때문이다.
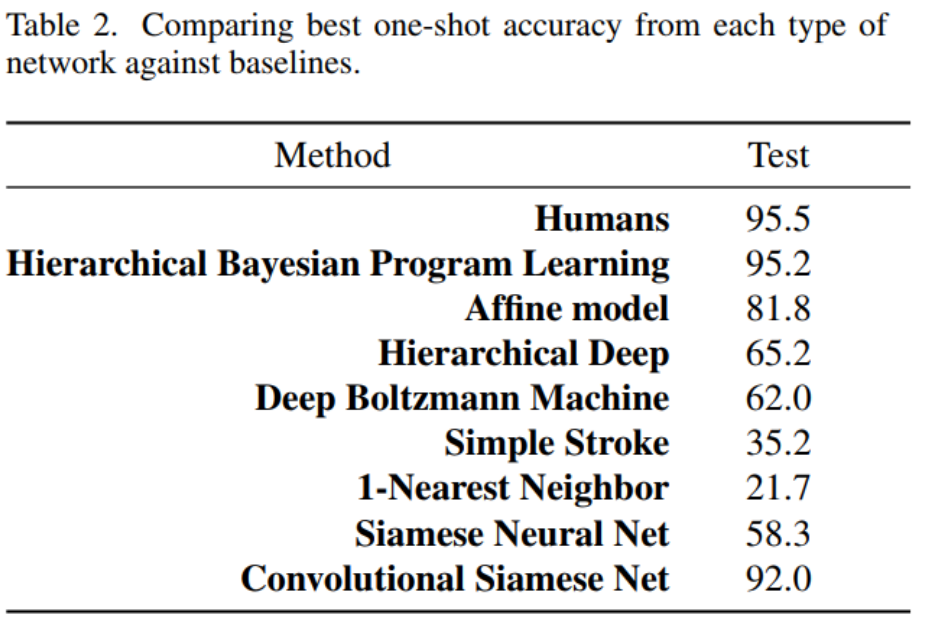
Test 결과를 보면 HBPL이 가장 훌륭한 성능을 보이고 있으나 HBPL은 알파벳의 획 순서, 방향 등과 같은 추가적인 정보를 가지고 있지만 Convolutional Siamse Net은 extra 정보 없이 92%의 성능을 달성한다.
추가적으로 transfer learning 없이 MNIST dataset도 10-way 1-shot classification을 진행했는데 1-Nearest Neighbor보다 더 좋은 성능을 보였다. 즉, 추가적인 학습 없이 Omniglot dataset으로만 훈련한 모델이 MNIST dataset에서도 어느 정도 훌륭한 성능을 보이고 있다는 것은 모델을 학습할 때 feature가 generalization을 만족스럽게 했다고 평가할 수 있다.
Reference
https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf
https://ai-information.blogspot.com/2019/07/meta-002-siamese-neural-networks-for.html
https://3months.tistory.com/507
https://medium.com/mathpresso/샴-네트워크를-이용한-이미지-검색기능-만들기-f2af4f9e312a
'Machine Learning > Meta Learning' 카테고리의 다른 글
| [논문 코딩] Prototypical Networks for Few-shot Learning (0) | 2021.02.13 |
|---|---|
| [논문 리뷰] Prototypical Networks for Few-shot Learning (1) | 2021.02.07 |
| [논문 코딩] Siamese Neural Networks for One-shot Image Recognition - Pytorch (1) | 2021.02.07 |
| Meta Learning (1) | 2021.01.13 |




댓글